A Little Specialism Goes A Long Way
One of the things most lauded about Hadoop is the concept of building your cluster on commodity hardware. This drastically reduces the cost and specialist knowledge required to build one. In this article however, I want to discuss whether this principle has been taken too far and is in fact restricting the possible capabilities of your cluster in the modern world.
What is ‘Commodity’?
First let’s look at the reasons behind choosing commodity hardware. The least contentious and also most obvious of these is price. Engineered systems are expensive whereas off the shelf hardware is not; however, if cost/performance were the only metric then no engineered systems would exist or they would demonstrate a considerable advantage in cost/performance. I would suggest that specialism in the design and engineering of such systems is also a key factor. After all, if a server fails it’s much nicer to be able to order one for the next day and slot it in than to wait for it to be built to order; and it’s nice not to worry about what impact new machines will have on your custom network infrastructure.
That said, I think it’s time we re-examine the definition of commodity in the modern world. For instance, would you now consider a RAID controller for your disks to be specialist? I have a pair of disks in RAID 1 under my TV at home, which doesn’t get much more commodity than that. For problems where read speed is your bottleneck (a LOT of big data problems), this technology is cheap and can provide real benefits.
RAID 1 has the advantage of providing better throughput on read, roughly equal to the amount of disks you have. This removes the I/O bound on read, but hurts write I/O. Hortonworks recommend using JBOD in their clusters. In JBOD, you take multiple physical disks and create one virtual drive. This has an advantage over RAID 1 as you also get an increase in write throughput in addition to the benefits on read. In the Hadoop world, we don’t care about individual resiliency, so JBOD would be superior.
What about a less obvious technology, such as the GPU? I can go to PC world and buy a GPU with 2000 CUDA cores for less than £500, which is considerably less than a single XEON for my server. And that’s just looking at the gaming focused cards. For the right problems (not as many big data problems), these cards can offer unbelievable performance. Is it not worth adding one to the commodity system?
The I/O Bound Cluster
Let’s look at an example like cluster X below. It’s a standard Big Data setup on commodity hardware:
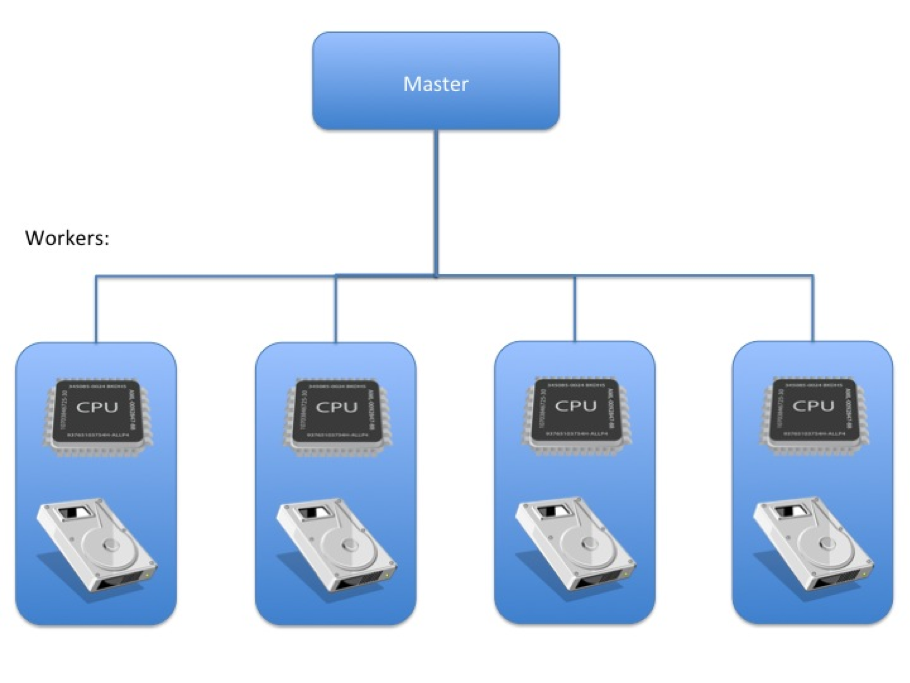
Cluster X has 4 worker nodes with non RAID disks and average CPU capacity. It has been designed and implemented well, but it’s I/O bound. The read capabilities of the commodity disks are not able to keep the CPU busy, so the expensive CPUs are often idle. What can be done? Buying more specialised high performance disks would certainly help but better is to try a JBOD setup:
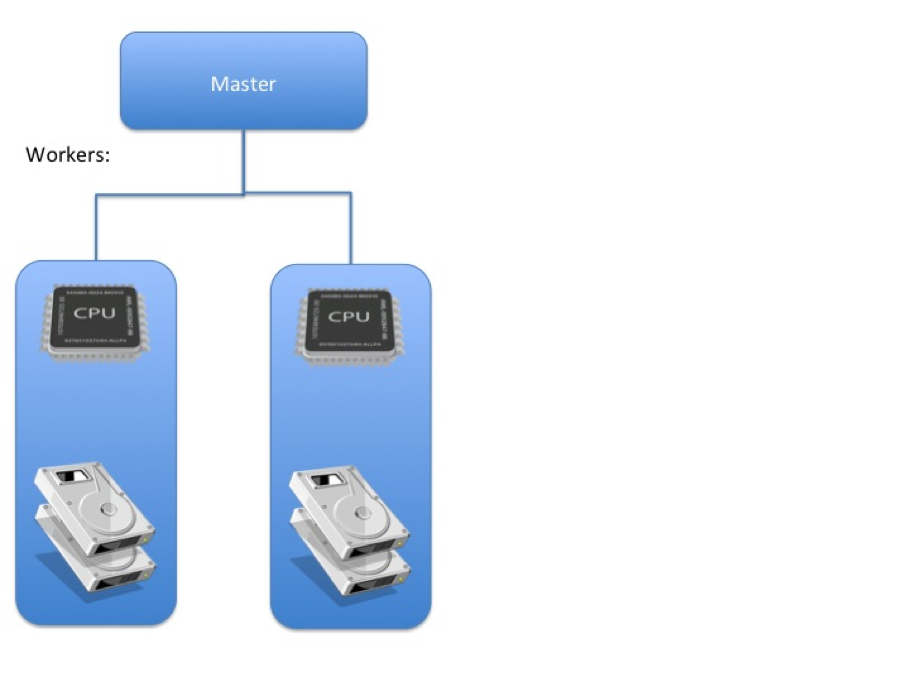
The first thing you’ll have noticed is that half the nodes on cluster X have disappeared and the number of disks has doubled. This is because each node now holds double the data in a JBOD array, enabling a theoretical doubling of the read/write performance on each node. The same data capacity is available across a smaller cluster meaning that the CPU to disk ratio has dropped, with the raised I/O capacity, each worker will be far more capable of providing data to keep those CPUs busy.
We could go even further; if we were to use more, smaller disks we could increase the performance even more. For instance, we could have two nodes running 4 1TB disks rather than 2 2TB disks. This would spread the data even more, thus allowing for a theoretical further doubling of I/O speeds. To get the best performance from the cluster we should keep adding smaller disks until it becomes impractical from a cost point of view or until the CPU is saturated. The result of this is that I/O is no longer the bottleneck and the remaining CPUs have more data to crunch than they can handle: cluster X is CPU bound.
The CPU Bound Cluster
To solve this lets explore the possibility of adding a GPU to each node:
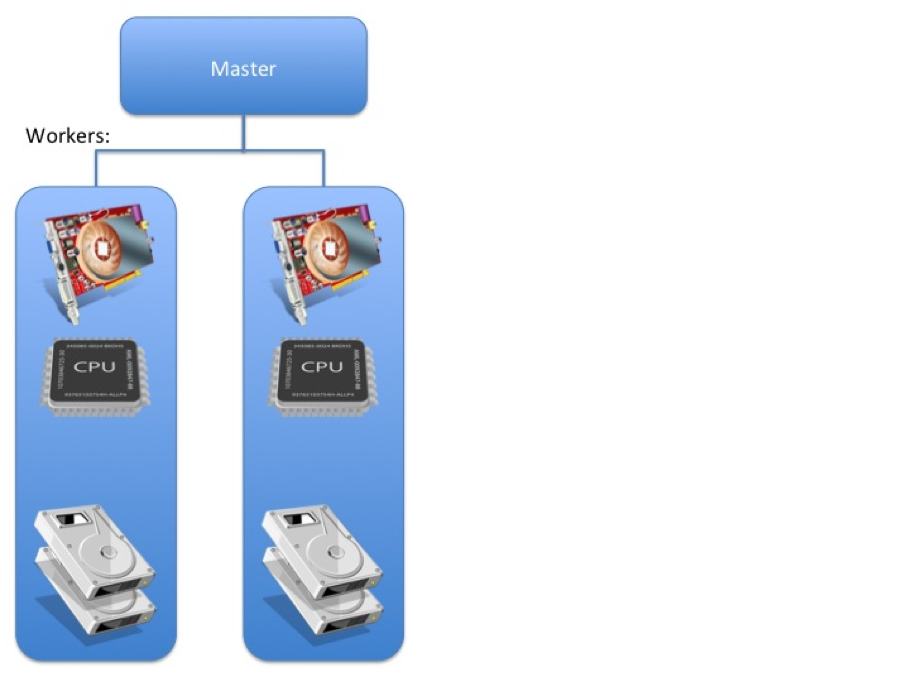
With the extreme performance that GPU processing can give you, it is likely that Cluster X is now I/O bound again, and this cycle can be repeated until the requirements of the cluster are met.
This bares mild similarity to CPU manufacturing. At the turn of the century both Intel and AMD made fast, single-core processors. For instance, the Pentium 4 family of CPUs were only single core, but had a frequency of up to 3GHz. After this, manufacturers stopped trying to increase speed, but moved sideways instead and increased the amount of cores on the chip. This gave them increased performance, even with lower frequency cores. This cycle is what were are attempting here, only on a macroscopic level, rather than the microscopic.
Cost vs Benefits
Returning to the subject of cost, we may have spent extra money on GPU and disks; but in the modern world these are not expensive and we have halved the size of the cluster, so the cost implications are not massive. You may say that enterprise versions of these components are very expensive and they can be, but you don’t need to invest in expensive specialist solutions for the same reason you do not invest in expensive specialist disks in the first instance. Fault tolerance is provided by the Hadoop platform, so you don’t have to protect against data loss in the same way as you may have to on other engineered systems.
Whilst we are on the subject of Hadoop, let’s have a look at the benefits the third iteration of cluster X has over the first. Advantages in compute performance are obvious, but what is perhaps less obvious is the advantage in data locality and network performance. Simply put, there are fewer nodes and so fewer places for data to located. This means it is more likely that the piece of data your job is reliant on is on the same node and hence a network hop is not required. This drastically improves performance in the combiner and ‘shuffle and sort’ stages of traditional mapreduce jobs and, because it is done at a hardware level, it is easy for more complex frameworks like Apache Spark to take advantage of it as well.
In summary, the principle that Hadoop should run on commodity hardware is a valid and powerful one; however, it may be worth revisiting what the definition of commodity hardware is.