Towards a realtime streaming architecture
Those of you following closely may have heard our talks and presentations about Spark streaming and how we were using it with Drools to do realtime decisioning and promotions. This worked but it performed pretty poorly; Drools meant that the Spark applications used a large amount of memory, and we were tied to a fairly old version of Spark that has known memory leaks in key areas. Spark also has other problems, it doesn’t actually provide streaming capabilities - it runs in microbatches; with a microservices architecture the data would pass through several Spark applications, and this would add tens of seconds to the end-to-end flow . As with everything in the big data sphere, the options available to us rapidly changed during the development of our Spark/Drools solution to the point that it became beneficial to switch to a newer framework.
Most of our streaming data is in the form of topics on a Kafka cluster. This means we can use tooling designed around Kafka instead of general streaming solutions with Kafka plugins/connectors. Kafka itself is a fast-moving target, with client libraries constantly being updated; waiting for these new libraries to be included in an enterprise distribution of Hadoop or any off the shelf tooling is not really an option. Finally, the data in our first use-case is user-generated and needs to be presented back to the user as quickly as possible.
This leads to a rather narrow set of requirements, and there are a couple of options here that fit really well. But first, what are the options we rejected?
| Solution | Rejection reason |
|---|---|
| Spark | Memory hungry, microbatches rather than actual streaming, requires experience of Hadoop to use well |
| Flume | Fine for simple ingest, but difficult to extend and lags behind on Kafka client support |
| Node | Some of our front-end developers do actually use this, but as it doesn’t run on the JVM you don’t get good support for the latest Kafka client libraries |
| JRuby | We use this quite a lot within our data tribe, and it works for putting small amounts of data into Kafka, but not at scale |
| Flink | We were quite excited about Flink, and may revisit it at some point for the CEP (Complex Event Processing) support. But for now, there are simpler options. |
| Nifi | Lacking support for the latest Kafka client libraries, plus there are simpler options for just Kafka ingestion and processing |
| Samza | Runs on Yarn, requiring a Hadoop cluster |
| Storm | Similar to Flink but not as good |
Chosen Solutions
Our chosen tooling for realtime streaming is a combination of Kafka Connect and Kafka Streams, falling back to Akka for when we are not directly dealing with Kafka.
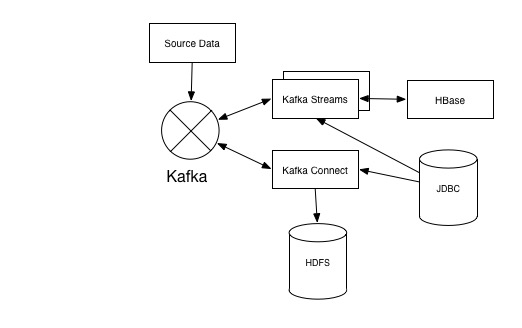
Our general pattern is to use a number of Kafka Streams applications to convert, process, and enrich data. This data is stored back onto a new Kafka topic, and may use data from HBase to enrich. We plan on moving from HBase to KTables in the future and expect this to give us a performance boost. Kafka Streams for this makes working with Kafka data really simple, it’s just a few lines of code to connect to and start receiving messages from a Kafka topic; whilst the documentation on getting started isn’t great, once you have one Kafka Streams application written the rest are really easy.
The main drawback to Kafka Streams is that it only works as a Kafka consumer. If your pipeline is based on any other data source, be it another streaming source like RabbitMQ or datastore like HBase, you need another framework. For this we use akka. Akka is a lot more complicated to work with than Kafka Streams, but it is a lot more flexible and there are a lot of good libraries for working with it. The main akka application we have in place at the moment is a Rest HTTP api which gives access to some of the data we have in HBase.
We also use Kafka Connect to drain down the final Kafka topics in the data flow to HDFS as well as Oracle. We are running Kafka Connect in distributed mode, which means that when another team create a new Kafka topic we can start draining that down really simply (assuming it is in a good format, if not we need Kafka Streams to do some conversion). Whilst we have discussed our preference for realtime streaming over microbatches, writing data to HDFS is actually the one good usecase for microbatching. Lots of small files on HDFS is slow and causes high memory usage in the namenodes, so bigger files are better. Our pattern here is to write files to HDFS as big as Kafka Connect memory allows, and then regularly run a Hive compaction job to concatenate the files into files of around twice our default HDFS blocksize.
We run all of this on Docker images, which makes it easy to develop against locally. In our git repository we have a Dockerfile that lets us use docker compose to start a local Kafka instance and related services as well as our applications.