Overlay network performance testing
As one of the engineers working on our next-generation platform in the Bet tribe of Sky Betting & Gaming, I was tasked with choosing an overlay network for our container scheduler (we’re going with Kubernetes but that’s a story for a different post). But just how do you choose an overlay network for a platform when you don’t know exactly what will be running on it yet? Here’s how I went about it, some stats and some conclusions I came to.
What is an overlay network?
Look out for a further post about container schedulers and why we chose Kubernetes in the Bet tribe, but effectively an overlay network allows containers to appear as if they are on the same network even though they may be running on different machines, even in different datacenters. You can think of it as a VPN between containers without the encryption overhead (you can even have encryption on it but most people don’t.)
What are the options?
It turns out there are a wide variety of overlay networks to choose from and they all have different characteristics. The current networking model for containers (e.g. Docker and Rkt — CoreOS’ similar product) is called CNI and theoretically any overlay network that is CNI-compliant can be used in Kubernetes. The first wave of cutting down these networks is by ease of install — If I’m going to be testing networks en masse, I don’t want to be spending days installing a network tech to find it’s not suitable.
This meant a much smaller list to benchmark — the ones that had kubeadm* addons that can be installed quickly on a disposable cluster. This list is :
- Flannel — the default CoreOS (what we’re probably going to use as our base OS) overlay network
- Calico — the first major overlay network to have network policy support (ACLs for network, similar to firewalls)
- Canal — This is effectively Flannel’s overlay network with Calico’s policy model, and is so similar to Flannel it’s probably not worth testing
- Weave — Another good alternative that has network policy support built in
- Romana — This turned out to be not an overlay network per se, although it is a networking layer, but was later discarded because we want an overlay network
*kubeadm is Kubernetes’ rather clever “setup wizard” type tool which allows you to set up a Kubernetes cluster extremely quickly.
Requirements other than performance
- Sky Betting & Gaming exists as a regulated business so we do require our new platform to have network policy support from the get-go:
- We also have to be able to explain the stack to all our on-call engineers, so the simpler the better;
- Our newest datacentre is being set up with Cisco’s ACI kit so support for that would be nice to have, but not in any way a necessity;
- The network must work in AWS as that is where our initial deployment will be, so it can’t interfere with AWS’ networking.
It turns out, other than the ACI nice to have, the three we whittled it down to all cover those if you add the Calico policy model to Flannel.
How do you test network performance?
I have learned everything I know about networking by osmosis and doing. This puts me at a disadvantage when it comes to network performance because that’s usually “Somebody else’s problem”. Not this time; this time it’s mine. Oh well, that just makes it a learning opportunity!
Having done a fair bit of reading and looking at the tools available to test the various networks, I settled on the fine tool iperf3 which specifically allows us to measure using UDP and measure jitter (which I knew to be a bad thing, but didn’t have a good grip on what it was before reading about it).
To ensure that the test was across availability zones* in Amazon (profile for worst-case, it can only get better!), I used a container replica set of 3 on a kubernetes 3-worker cluster with each worker in a different availability zone. *Availability zones (AZs) in Amazon are theoretical boundaries between it’s “datacenters”. Theoretically, no more than one AZ will ever be down at once but it does create network overhead.
I then ran iperf3 as a UDP client and asked it to attempt to transfer 1, 10, 100 megabits/s and 1 and 3 gigabits/s to give a range of data for each overlay network. Also for comparison, I did the same test for AWS instances without an overlay network and a test in one of our non-cloud datacentres.
One of the things about running on AWS is that the instance size makes a difference to the network throttling that Amazon apply, so I ran the Weave test and the plain AWS networking test a second time, running on an m4.xlarge cluster rather than an m4.large.
The final thing to note in terms of methodology is that these networks have all been tested with out-of-the-box settings, specifically the settings provided by the addons linked to on the kubernetes addons page. I’m sure that tuning and tweaking these network addons would provide different results, however, there are not enough hours in the day to work through all the permutations. As always, your mileage may vary and you should not assume that these results apply directly to your setup.
The data
The raw output of iperf3 output looks somewhat like this :
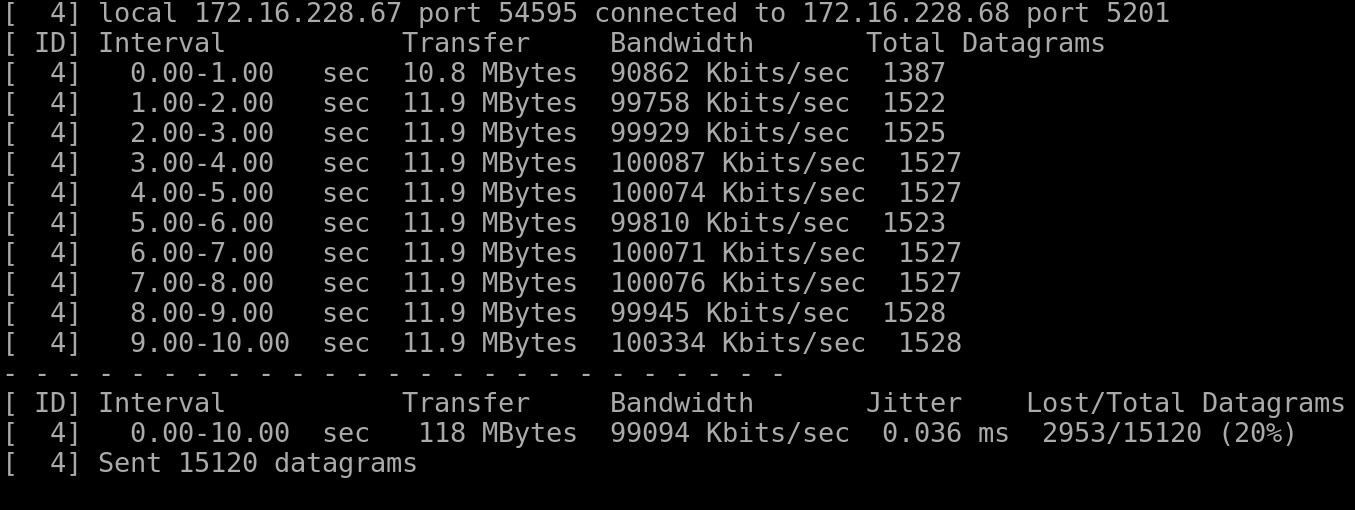 I tabulated this data per Network and it looks like this :
I tabulated this data per Network and it looks like this :
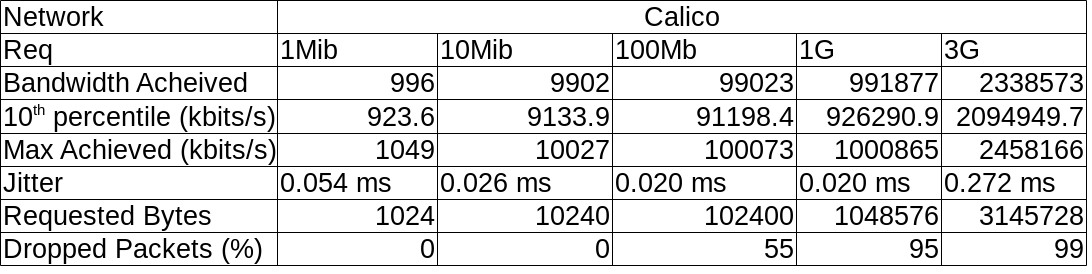
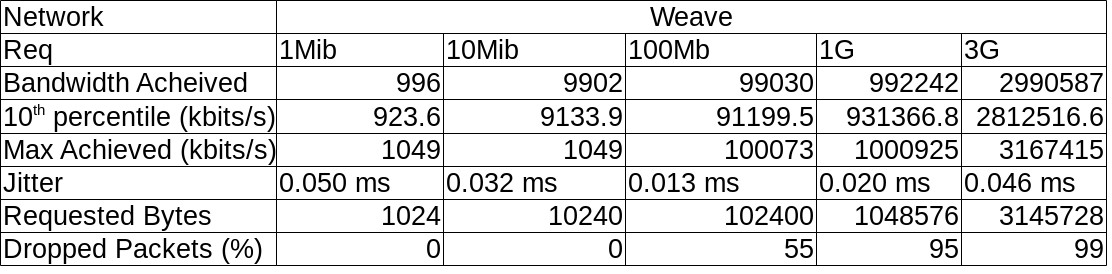
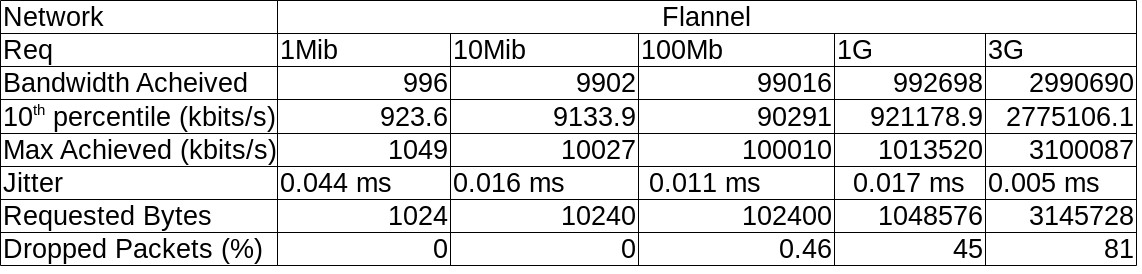
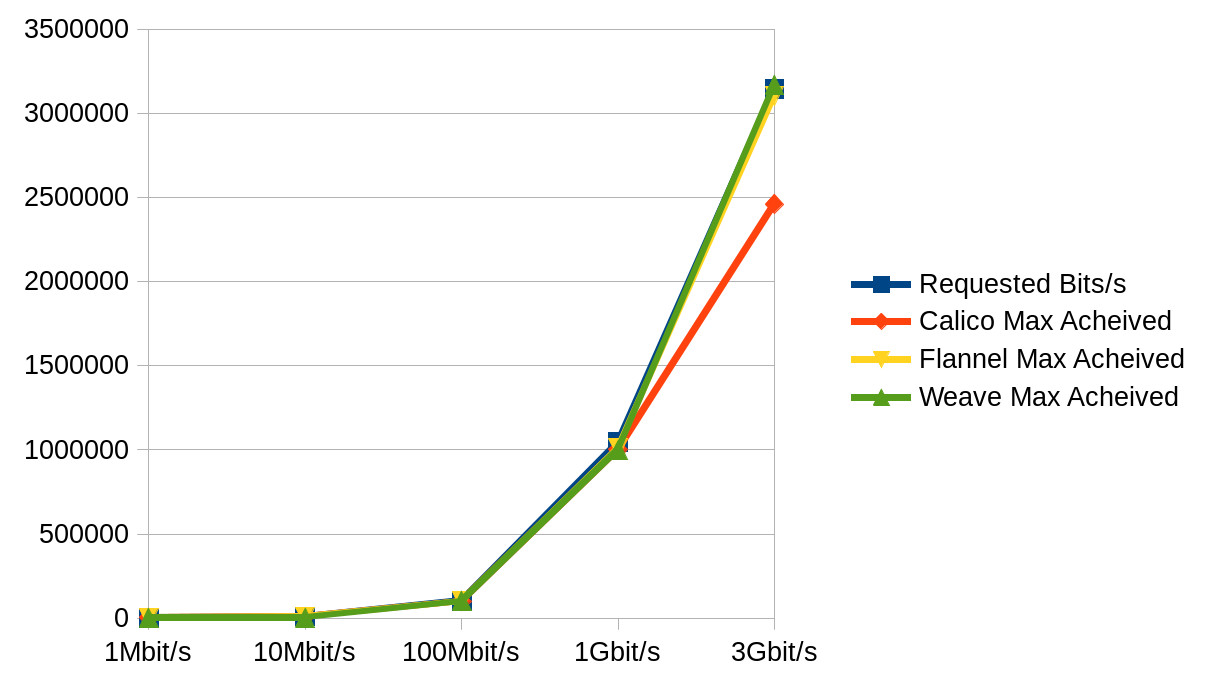
Some (not so pretty) graphs :
Max Speed Acheived
 Normalised Average Transferred data
Normalised Average Transferred data
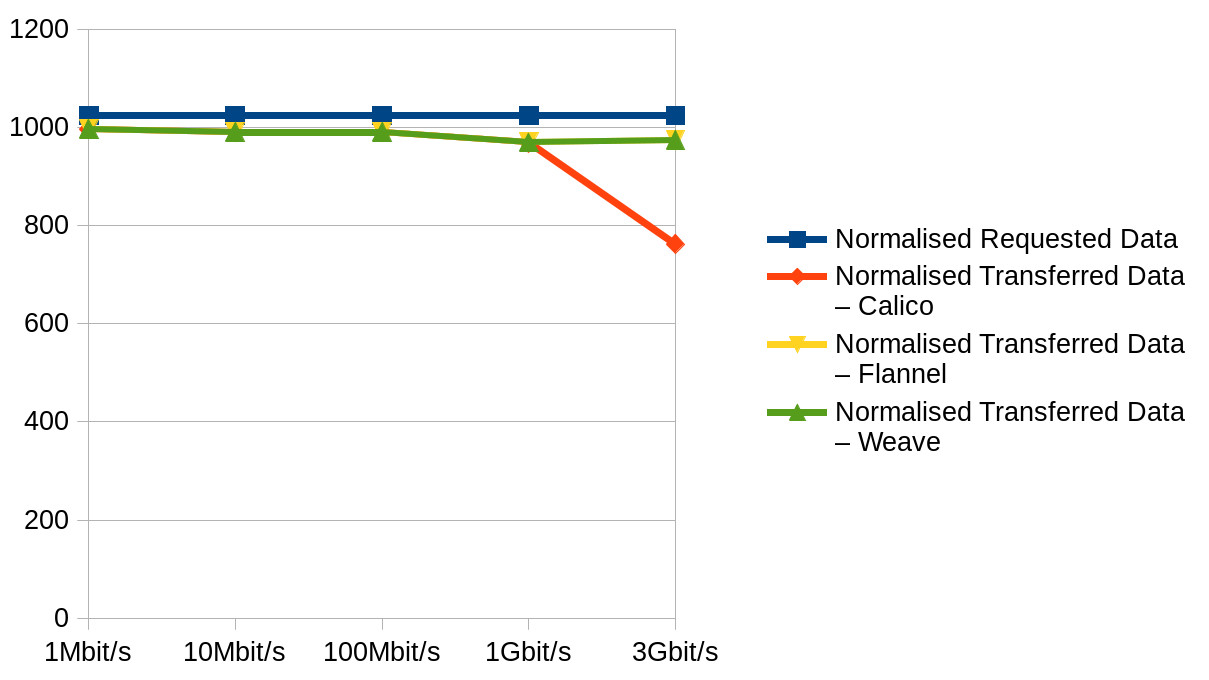
It turns out that making graphs of summaries in Excel (LibreOffice really) doesn’t do much for the presentability of highly technical data.
Conclusion
Given our current setup is Kubernetes on CoreOS ContainerLinux and ContainerLinux default is Flannel overlay and Calico policy, what we have decided to do is… nothing! The exercise has shown that all the mature overlay networks are similar performance-wise with the exception of Calico, and there’s no compelling reason to switch.
If you are looking for which you should use in a different scenario and have no preferences, I’d recommend Weave, but purely because I had a struggle to get Flannel to work using the addon model and calico topped out first at transfer speed.
And Finally… Interesting lessons learned
- Be sure to check your hosts have the “Check Source/Dest” disabled if you’re running an overlay network on AWS or you may have issues. Unfortunately there’s no way to set this on an ASG/Launch config level, so if you want to auto-scale, you’ll need to give the hosts permission to set this on boot.
- Calico did happen to go non-responsive on one host machine multiple times during my tests, but I didn’t really have time to investigate why, and I’d got the performance data I needed, but it’s another reason I wouldn’t feel comfortable choosing that tech.
- Keep your eye on your network as well as CPU utilisation on your container clusters if running on AWS — consider upgrading to the more expensive hosts if you see latency issues.
- Flannel can be a pain to get running, especially in AWS, I struggled to install it in the same way as the others to keep the data equivalent but fell back to running it in the “CoreOS” way.
- Once you hit 100Mbits/s of UDP traffic, packet loss hits you, hard. This was borne out in testing not only on AWS but also on VMWare, so it isn’t something “new” about overlay networks but is interesting.