Implementing The Schema Registry

Introduction
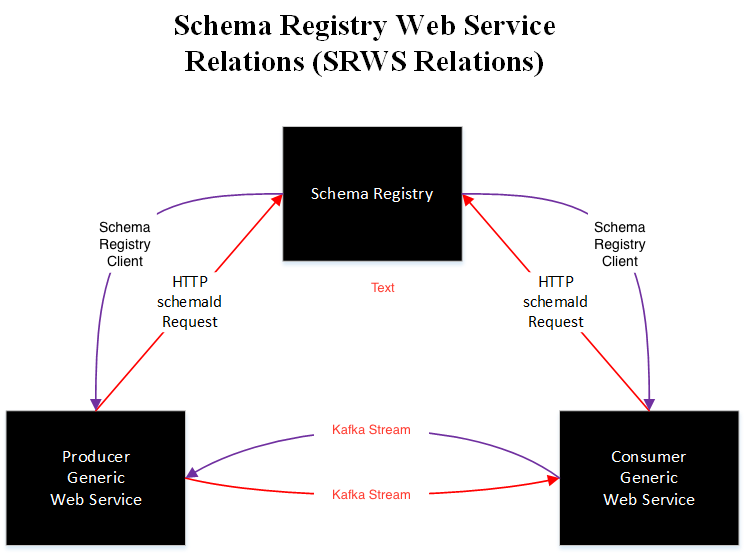
The platform currently used within the Gaming Promotions Squad largely relies on Apache Kafka. Kafka is a data streaming service which is used to send data from one section of the stack to another. Apache Kafka works with Apache Avro, a data serialization system used to encode event data placed onto Kafka. As a result of using Avro we need to use a Schema Registry Service, this service will store the various Avro schemas that we require in order to encode and decode messages.
What it is
The Confluent Schema Registry is an idea by the creators of the Kafka platform. It is a secure and safe way of storing schema versions and ensuring that an accurate history is kept in case a rollback is needed. The schema registry is stored in the _schema topic, which is on Kafka itself. So anyone who has access to Kafka will therefore have access to the schema registry. This gives us the Gaming Promotions Squad, end-to-end schema availability meaning we can massively increase the reliability of a system.
A simple glance at a kafka pipeline
Why we need it
The main reason that this work was needed was to ensure uniform schemas across different areas of the Kafka stream, so every team within the process has the same version of the schemas. Using Kafka, one squad might put an Avro encoded message into the system, at the same time another squad will consume the message and attempt to decode it. This is where problems may arise, as currently at this point in time schemas are stored on disk. This means that if a team updates their schema, and pushes their changes without properly informing a another team in the pipeline the entire system can flop. Consequently, a successful data streaming platform could quite easily topple due to mismatching schemas (Oh no!). Yet, once the Registry is implemented fully, it will give all teams the ability to utilise the same schemas, as well as cutting down on disk load times.
How we do it
Our Registry client was built to spec with the Confluent Schema Registry. For the development of the client we have used NodeJS; using a Node package ensures it is reusable to deploy by other teams. When looking into the use of Node we realized that there were disadvantages, such as language native functions, specifically data serialization. However, we believed this was offset by the obvious advantage of having the use of NPM. NPM would be used to combat the native deserialization functionality by using the AVSC package. This package is an implementation of the Avro specification, which specifically uses JavaScript. This use of JavaScript allows commonality, thus making it easier to encode and decode messages sent in Avro, provided the correct schema is given.
The main part to the Schema Registry implementation is the client, it is a layer on top of the Schema Registry Restful Service. The Node package interacts with the Registry Service to return schemas to the client. Once retrieved the package then caches the schemas to ensure it’s as efficient as possible when it comes to timings and network resources. Once cached it then passes the schema to another package, which in turn is resolved into a promise of an encoded or decoded message back to the consumer of the package.
The Confluent Schema Registry has a specific format in which messages should be encoded, this is called the ‘Wire Format’. The wire format is essentially a way of ensuring that all encoded messages sent include some form of identification in how they were encoded for the schema to read. The format contains one ‘Magic Byte’, known as the Confluent serialization format version number, this is currently always 0. Additionally, this is followed by the schema ID which has a format of 4 Bytes.
Overview
The Schema Registry is essential to teams using Apache Avro and Kafka to stream data from one end to another, the registry makes the encoding and decoding of these messages much more reliable and easy to collaborate on. The registry holds all different versions of a schema and can be accessed by anyone relevant to the Kafka stream. The schemas are then used to encode and decode Avro encoded messages, usually from Kafka.