FireDrill GameDays at Sky Betting & Gaming
The FireDrill GameDay
Here at Sky Betting & Gaming, we’ve had great success running fire drills against our production systems. By running these failure scenarios we’ve been able to increase confidence in our ability to support live service, enhance the knowledge of support staff and highlight weaknesses - be that with the services themselves or our support processes.
Looking to build on this success, I put forward the idea of running similarly structured events pre-go-live in the form of a GameDay. The aim was to gain similar learnings but by doing it before the system went live we sort capture issues in their infancy, before they have a chance to impact customers, and help make a judgement call on the service’s readiness to go live - thus the “FireDrill GameDay” was born. In this post, I’ll summarise some of the key elements that made these events a success and highlight some of the lessons learned from running these over the last two years.
A FireDrill GameDay brings together two activities in Chaos Engineering :
- GameDay: purposefully creating major failures with the goal of increasing reliability. Typically, they last between 2-4 hours and involve a team of engineers who either develop an application or support it.
- Fire drill: routine and random testing of the failure modes of systems you build and the processes you use to support and secure what you have built. Deliberately disrupt part of a functioning system to see whether, and how, it recovers.
A Firedrill GameDay is essentially a GameDay run using the tried and tested format we’ve developed for fire drills; as such, I’ll refer to them as GameDays for the remainder of this post. What makes the format slightly different from our standard fire drills is that they are less formal, have multiple scenarios, and in our case performed on pre-live systems.
In regards to planning and execution, we found it useful to include the following elements:
Scope
By clearly defining the scope of the GameDay we can ensure that we focus on the correct areas of the service with the appropriate participants. The scope would generally cover all components of a given service but you may choose to focus on areas of a service where the risk of failure is high or the state of readiness (to go live) is questionable.
Participants
Those involved in the GameDay should be notified at the earliest opportunity to ensure they are available and preparation can start at the earliest oppotunity. Generally, involvement would be limited to those who are to be responsible for supporting the service and those involved in its development. The support team would primarily be involved in the investigation and resolution of incidents and the development team involved in planning and reviewing outcomes.
One or more Excon’s (exercise coordinator) will be required to run the incidents and it’s also useful to assign someone to the roles of SLM (Service Lifecycle Manager) and IC (Incident Commander).
Timetable
In advance of the GameDay publish a timeline of how the day will be broken down. Ensure that sufficient time is provided to investigate each issues, attempt to find a solution, and confirm that everything is back to normal. It is also advisable to have a break in between each scenario to reset the environment and give those running the GameDay a break as well as time to prep for the next scenario.
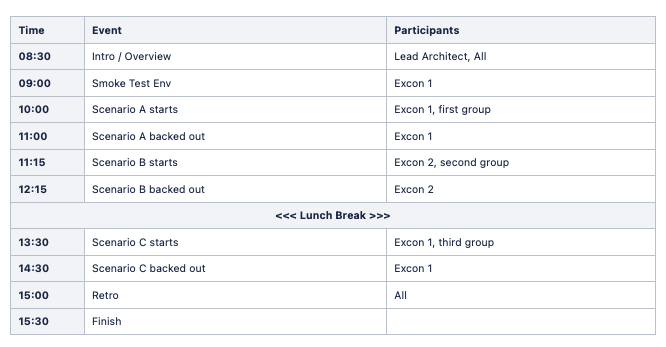
Intro / Overview
Kick off the GameDay by providing a run down of the day’s plans and an overview of the system architecture. This is particularly useful where the target system is yet to go live and the support personnel are unfamiliar with it. Having the architect or lead developer provide this overview may be particularly beneficial as is the provision of links to useful resources such as runbooks and monitoring.
Scenarios
Multiple failure scenarios to be devised and and tested well in advance, while ensuring they are kept hidden from those resposible for resolving the problem on the day. Devising the scenarios should be a team effort involving analysis of the system architecture and failure mode. Issues experienced during development should be used to pinpoint potential problem areas. Ultimately, a list of scenarios should be broken down and detailed as shown here:
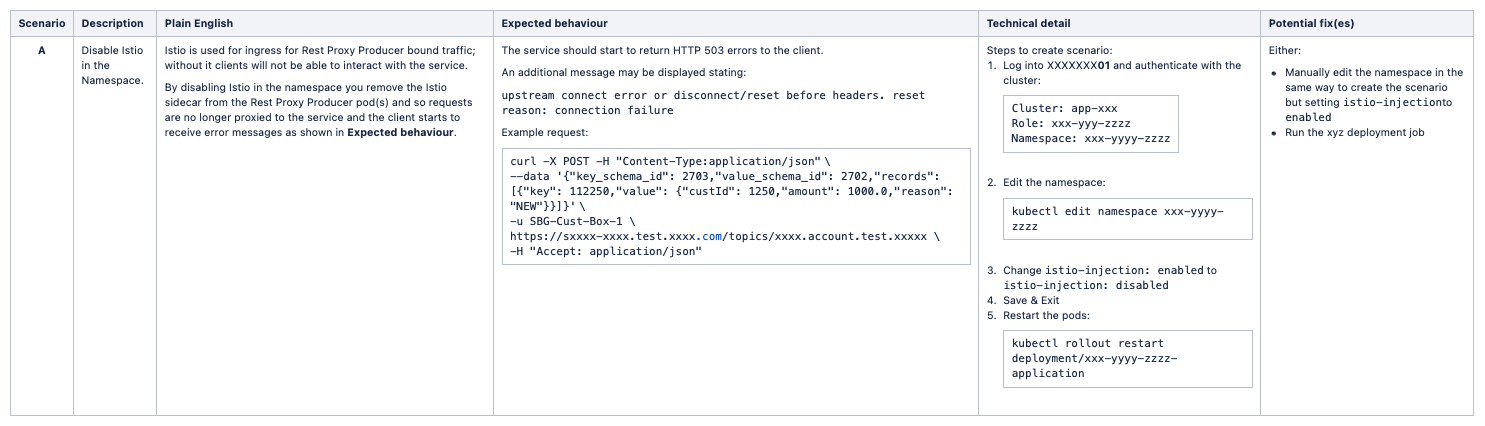
The selected scenarios should be thoroughly tested to obtain a clear understanding of how the simulated incident will play out and the best candidates taken forward to the GameDay.
Certain scenarios may benefit from simulated transactions being run against the service. This adds to the realism, with logs being populated with associated errors/warns, while also helping sign-posting the issue and its consequences.
Execution
During execution be clear on any rules that might apply e.g :
- This GameDay will take place in the DR environment and be treated as if a live incident though all participants will be aware it is just a test exercise.
- Responders will be called out using Slack, assuming nothing automatically calls them out.
- The Excon may drop hints where necessary and produce updates on the time remaining.
During the exercise, it is good to keep reminding the participants of the questions we are seeking answers to :
- Is system behaviour as expected?
- Do you have the required access to services to investigate the issue?
- Is the monitoring sufficient to detect the problem?
- Do the monitoring dashboards aid insight and investigation?
- Do alerts trigger as required and resolve following the incident?
- Do you have visibility of the logs and did they help highlight the issue?
- How good is the supporting documentation e.g architectural, support, etc?
- Are there any issues with the incident management process?
- Are there any areas we can change to improve the supportability of the service(s)?
- Is there a clear understanding of the impact of the incident esp on the customer?
- Does the service recover gracefully with acceptable impact?
Retrospective
Once all the scenarios have been executed those involved should be given time to take a break and consider any issues encountered especially in response to the questions asked in the previous section.
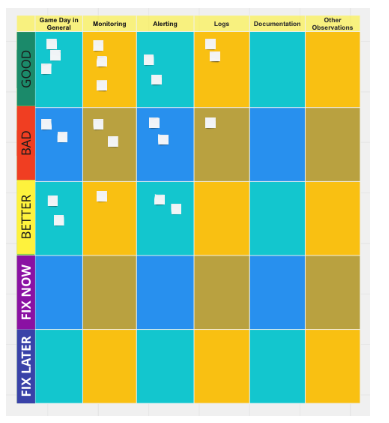
A retro board similar to the following may be used to decide which issues are to be fixed now and those which can be left until later:
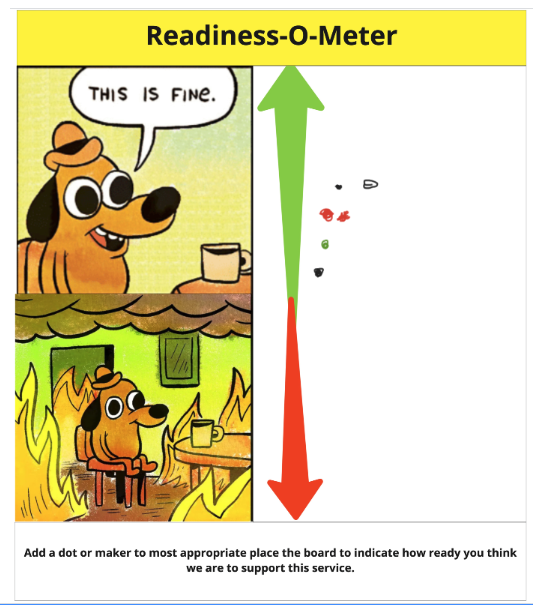
We also made use of a Readiness-O-Meter to get a quick view of where people thought we were in regard to our ability to support the service.
Lessons Learned
Having now run several of these events - here are some of the key lessons learned:
-
Early involvement is key - start early in the project and get people involved from the outset. The GameDay should be treated as a project deliverable in its own right.
-
Choose scenarios wisely for maximum learnings on incidents that are likely to occur. This ensures you provide valuable insights into the service and how it is supported.
-
Devise multiple scenarios - not only will you need backups but the more scenarios, the more you’ll learn about the service and the greater the potential for uncovering issues.
-
Resist efforts to include tests that should be done elsewhere; the GameDay is a complement not a substitute for more traditional forms of Operations Acceptance Testing like failure testing, backup recovery, and DR testing.
-
During the exercise do not lose sight of the end goal - keep reminding the participants of the questions we are seeking answers to e.g. Is system behaviour as expected? Are there any areas we can change to improve the supportability of the service(s)?
-
Make time for a closure-type event and associated activities ensuring that nothing gets left unresolved and without an owner.
-
Finally, the day of the GameDay is just a part of it - as important are the conversation, analysis and testing that happen in the lead-up.