DevopsDays London 2017
Introduction
Earlier this year I visited the popular DevopsDays conference, which had its London leg on the 6th - 7th of September. It promised an interesting lineup, and utilised an innovative split of its day between the more traditional talks in the morning sessions, and the ‘Open Spaces’ format in the afternoon (the afternoon sessions are split into eight rooms, and audience members are tasked with devising a topic and arguing for its inclusion. Each session lasts roughly 45 minutes per room, at which point a new topic begins). With speakers from The Guardian, The Financial Times and Pizza Hut, there was a wide range of opinions and viewpoints presented over the course of the two days.
Having not visited a Devops conference for at least two years, I was excited to see how the industry was progressing; though I wasn’t disappointed, it was interesting to see how the rate of progress seemed to be slowing compared to a few years ago. As you might expect, there was still plenty of talk about containers and their place within the industry, but now the focus was on ‘what and where next’, and ‘is there life after Docker’ (the answer for both is, of course, Kubernetes). There was also interesting discussion on ‘keeping things boring’, and several talks on methods for implementing and standardizing Pipelines as Code. This seems to be a real pinch point for much of the community at present.
Who are the Core Tribe?
Core are the Tribe that works across Sky Betting and Gaming – we ensure our customers can join us, transact, view and manage their account details in real time. Additionally, we’re also responsible for the tools and services we use to support our customers. One of the many employee benefits of working at SB&G is the Tech Ninja fund, which gives each member of staff up to £1000 each year, to spend on their choice of training or self-development (in my case, visiting this conference).
Let’s have a look at some of the key topics covered in more detail, and how they might impact the Core Tribe.
Kubernetes
The subject everybody was talking about. There were multiple strands around the subject – ‘where is future of the container industry?’, ‘what next for Docker?’, ‘why should I be using Kubernetes?’ – but a show of hands in a couple of the Open Spaces sessions showed that very few are using the technology in production (Kevin Bowman from Bet was one of the few participants to have in-depth knowledge of building and deploying Kubernetes in a live environment). On the whole these sessions had the early adopters extoling the benefits of the technology (network security policies, aggregated logging per cluster), and in particular its advantages over ECS and Docker Swarm (service discovery, intelligent routing and per node affinity rules). Some mention was also made of its inability to cope with ‘big data’ workloads – instead a combination of Mesos and Marathon was recommended for this.
What can we take from this? Undoubtedly Kubernetes is an exciting prospect, but one that is still in its infancy. It was telling how few are currently using this for production workloads – perhaps ‘boring is powerful’ after all. Which leads us neatly on to…
Boring is powerful
Jon Topper from The Scale Factory gave a great talk on the idea of keeping your platform ‘boring’, which can be split into two main ideas; first of all, that software is rarely complete right from the start, features are always added over time. As the ‘fashionableness’ of a product decreases over time, feature availability, quality, reliability, security and collective knowledge all increase. The release schedule of former industry darling MongoDB illustrates the point:
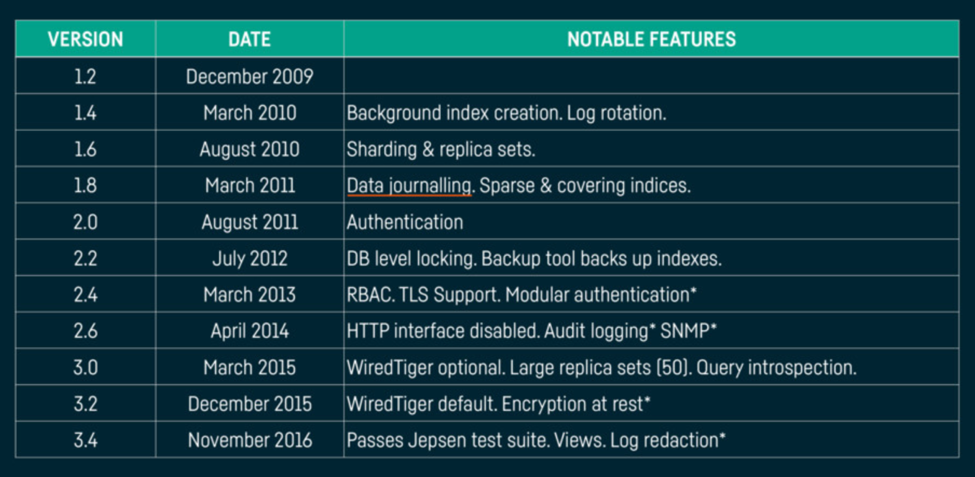
For example - MongoDB did not get data journaling until it was 18 months old…! But plenty of organizations adopted it long before that, and usually put measures in place to work around missing features. Which increased operational overhead, engineer fatigue, and in turn reduced confidence in the product. This really highlights how business context and considerations are always required, but not always met, when making design and deployment decisions. So, as the maturity of a product increases, and the community around it develops, it becomes ‘boring’. And the more ‘boring’ you have within your platform, the more secure and reliable it will be. This is a good thing, and it should be celebrated! Especially for the on-call engineers who can now enjoy a good night’s sleep.
The second main point of the talk was the contradiction that sometimes, yes, you will need to adopt new technologies. The speaker put forward the idea of ‘innovation tokens’, which similar to the SRE-style ‘error budget’ mechanism, allow a specific number of new projects per quarter, as long as they meet certain criteria; the project must be beneficial to you, as a key differentiator for your business. The project must be risk-worthy, and likely to give you a competitive advantage. The idea being that fewer products are adopted on the whim of one lead engineer, who having read a blog about the shiniest new app, immediately puts said app straight into production! Not jumping aboard the latest technology bandwagon is something we are already aware of – with the size of our platform, and the number of transactions we process at peak times, stability is our number one priority and this is helped when our engineers have in-depth knowledge of a product. There is much to be said for repeatable deployment patterns using familiar software packages!
Jon’s full talk is available below.
Pipelines as code
A couple of talks around CI/CD highlighted a problem that many are dealing with – Jenkins isn’t always the best tool for the job. Firstly, it was recognised that it is all too easy to allow your Jenkins server (and it usually is a single server) to become all-encompassing – build, test, deploy, archive – which then becomes a single point of failure; plugins, templates and build artefacts can be stored within the Jenkins ecosystem, and Jenkins isn’t the easiest to reliably restore into a consistent state. Secondly, being UI focused is a Bad Thing, as it promotes behaviours that shouldn’t be repeated – the ‘copy to a new pipeline’ workflow was called out specifically for being an anti-pattern, as it’s a sure-fire way to create pipeline mess further down the line. Pipelines templates (or shared libraries in Jenkins’ case) go some way to fixing this problem, but they still have to be updated and maintained regularly. Alternative products to alleviate these problems were discussed in one of the Open Spaces sessions; when faced with an open question of which CI/CD server supports approval gates and useful visualisations of pipelines, our own Wilb suggested GoCD as a viable alternative. Concourse CI was also strongly recommended, as it is YAML-based, and so allows easy server recovery and storing pipelines in version control. Finally, Spinnaker.io was recommended, which is being used currently by Netflix and Waze as they move their pipelines out of Jenkins and into a dedicated stand-alone tool.
What can we take from this? It’s important to remember that there are better, more specialised tools in the CI/CD space, especially for pipeline management and visualisation. And storing your pipelines and server configuration in version control is crucial as your CI/CD estate grows, and becomes integral to your organisation.
Not Wrong Long
A talk from Sally Goble, Quality Manager at the Guardian explained how they manage their perception of software quality, and how the role of the QA team changed when moving to a (very) continuous delivery schedule. At the Guardian they progressed from one release a fortnight to over 100 releases per day, which had a dramatic effect on their QA team - they spent a year building automated regression testing suites that did not work, at which point they realized they didn’t need them anyway. Their release schedule was fast enough to allow them to admit their software might not always be perfect, so problems could be fixed forwards instead. At which point they threw the automated regression testing tools away, and stopped doing manual feature testing too – this was reduced to the bare minimum.
They also removed the requirement for the QA team to perform this testing – the onus was moved onto engineers, product owners and managers. As they were freed from huge blocks of regression testing, they could focus on empowering other technical (and non-technical) staff to perform tests themselves, which improved quality. They created internal dashboards and quality ‘principles charters’, which other teams use to reference quality specifications of how pages and adverts should look. And they created bespoke synthetic monitoring tools, which repeatedly test user flows thousands of times per day.
They are careful to distinguish that every release is a single feature release only, which makes it easier to identify problems or roll back pieces of work. They use aggressive caching and extensive use of feature switches to add and remove features at will. They use App / Play Store beta programs, and in-app feedback reporting, to close the feedback loop between themselves and their users. And in an interesting move, their ‘user help’ team was integrated into the Development team, to close that gap further.
At SB&G we have multi-discipline squads within the Core Tribe, where QA resource is split evenly across each squad. We could take a number of these points on-board if QA were to become a blocker for a squad; empower the rest of the squad to share responsibility for testing, admit that software might not be released in a perfect state, but put more effort into finding problems before our users do, and establish closer links with our customer-facing support teams to find out about problems sooner.
Sally’s talk is available below.
Other highlights
Alongside the technical morning sessions, there were a few talks on more abstract topics. One discussed the benefits and drawbacks of remote teams versus collocated ones, and the need for the human element that needs to exist in each working environment. There was a lengthy talk on the issue of mental health within the industry, of how the withdrawn nature of IT staff can easily mask the danger signs of when they might actually be struggling, with some gentle advice for what to do if that occurs.
All of the morning sessions are on YouTube, available on the DevopsDays YouTube playlist.
And finally, there was a surprise winner in JFrog’s PS4 raffle!
We have a lucky winner @JFrog booth @DevOpsDaysLDN! Have fun with your new PlayStation!! #DevOpsDays pic.twitter.com/bhaW6Glh97
— JFrog (@jfrog) September 7, 2017