Optimising an AWS microservice - Part 1
In the Trading Models squad we build systems that calculate the probabilities of things happening in sporting events, and we use these probabilities to set Sky Bet’s prices. Recently, we’ve been building out a pricing service in AWS for Sky Bet’s RequestABet product - an API that our internal sportsbook platform can use to get the price of football betting opportunities as customers request them. One thing that’s different about this project for our team is that the traffic through our system will be customer driven rather than trader driven meaning that we need to serve requests fast, at large scale. In this two part post, I’ll take you through some of the optimisations we’ve made to our system to hit our non-functional requirements.
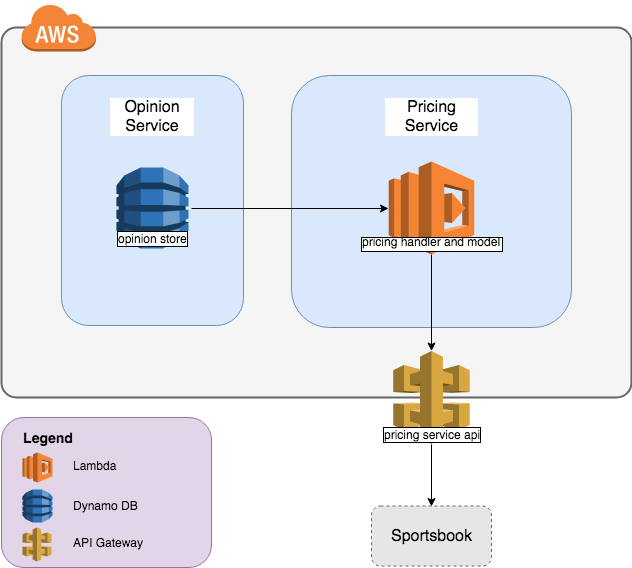
Our System
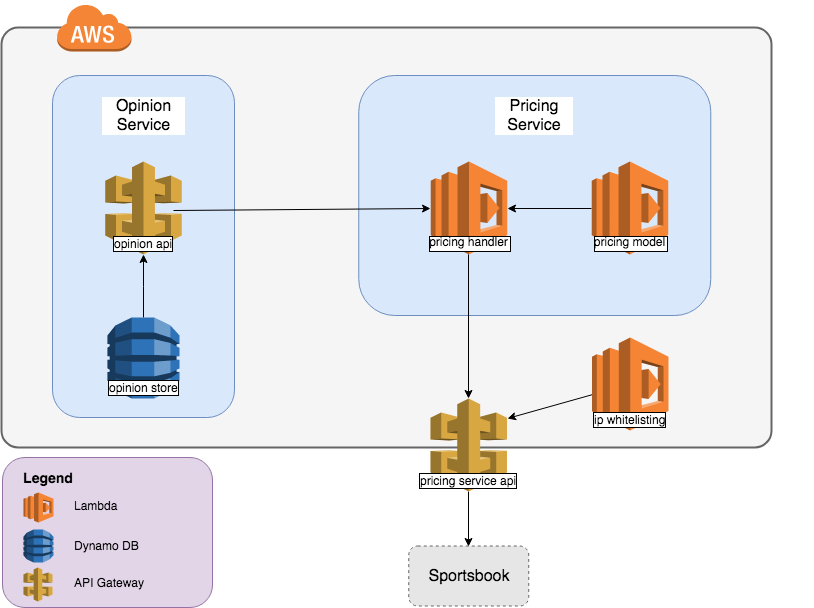
The above diagram shows our initial system design. There are three main components here:
The ‘Opinion’ Store
- ‘Opinion’ is our term for the trader inputs required for our model, i.e. a numerical representation of what we expect to happen in the game. It comprises things like the average number of goals we expect a team to score
- This is stored in a DynamoDB table fronted by an API that allows the traders to PUT opinion and our system to GET it when required
The Pricing Model
- This is a Java lambda - you pass it a description of what might happen in a football match along with the necessary opinion and it returns a price.
- For example, you might request “Leeds Utd to score 3+ goals” and it might tell you this is 2/1
- This includes some in-memory caching so that if a lambda instance receives two requests with the same opinion then it only performs the majority of the calculations once
Pricing Service
- This is made up of an API Gateway and Java/Kotlin lambda
- The API Gateway has a ‘Lambda Authoriser’ that ensures our system can only be accessed from whitelisted IP ranges
- It takes POST requests from our sportsbook, orchestrates the requests to the Opinion Store and Model and returns the appropriate response
“Make It Work. Make It Right. Make It Fast.”
Kent Beck
Whilst our first cut did include some in-memory caching in the pricing model, we didn’t put much initial thought into performance and focused instead on delivering a fully functional system for the Sportsbook team to begin testing against.
However, before going live to customers we were given a couple of NFRs to hit:
- We need to be able to handle 50 requests per second
- Our end to end needs to be under 100ms latency at the 95th percentile
- i.e. 95 out of 100 requests must be under 100ms
One of the best things about using AWS serverless systems is how well they perform at scale. AWS Lambda quickly scales outwards as it handles executions in parallel. You are given a soft account limit by AWS of 1000 concurrent requests so 50 requests per second wasn’t a concern for us. However, the latency requirement was a worry – the model alone takes several hundred milliseconds to calculate when handling a complicated request as it has to do some serious number crunching - so we set about writing some performance tests to put our system to the test.
Our Test Scenario
We wrote a performance test in Node.js that populates our opinion store with fake fixtures and then sends requests to our pricing service, recording the latency of each request. We estimated how our system will be used in the real world, skewed these estimates to give a ‘worst case scenario’ and used these to benchmark against. We also made sure that the dummy request we were making was something that touched all parts of our pricing model.
Running this test for the first time gave us a baseline 95th percentile latency of 280ms, a fair way off our target! Time to start optimising…
Let’s make it faster!
As a team we all got together around a whiteboard and sketched out all the changes we could think of to make our system more performant. We then scored each change on how much of an impact we expected, how much effort it was, and how sensible it was, before coming up with a rough order of what to try first.
Taking our lambda memory allocation to the max
This was the quickest and simplest improvement we could make – it’s one click in the AWS console or one line of terraform code!
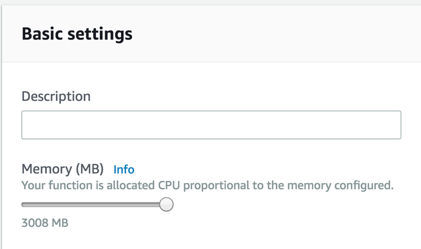
As you can see, the CPU that your function is allocated by AWS is “proportional to the memory configured”, so more memory should lead to faster execution times. An interesting side note here is that with lambdas you are charged based on a combination of memory and execution duration - GB-Seconds - so the increase in speed you get can actually offset the cost of increasing your CPU allocation. More on lambda pricing can be found here: https://aws.amazon.com/lambda/pricing/
Attaching a Resource Policy to our API Gateway
API Gateway is a great way to easily expose your Lambda functions over HTTPS, but it does mean that your API is open to the public internet, which isn’t ideal for an internal service like ours. When we first started working in AWS, their standard solution for this was IP whitelisting via what they call a ‘Lambda Authoriser’ (formerly Custom Authoriser). This is a lambda function that is executed every time the API is invoked, returning a policy for the API to evaluate. This policy includes your whitelisted IP range. See the following diagram from the AWS documentation:
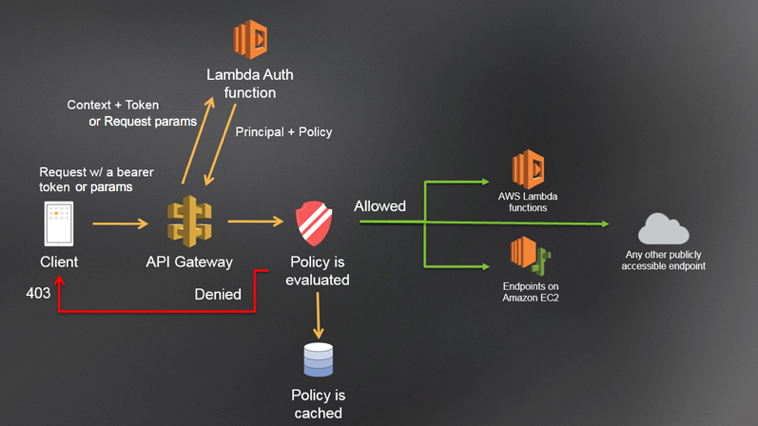
This seems a bit overkill when our policy is always the same thing on every invocation right? All we want to do is block stuff from outside the same IP range every time…
Well good news! AWS announced an update to API Gateway in April with a much simpler way to lock down your APIs - Resource Policies. This is where you attach a static policy to your API and it checks this without the need to go to an authoriser. In the AWS console, it looks like this: (IPs and Resource redacted)
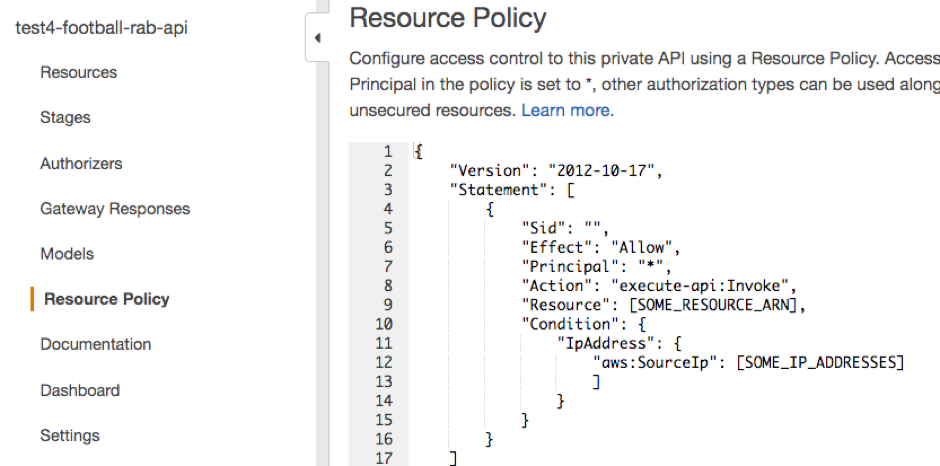
Adding this to our gateway cuts out a lambda invocation for each request, which takes us a bit closer to our latency target!
Cutting down the number of components
One of the core concepts of microservice design is that each component should do one thing and one thing only. However, with every boundary in our system we’re adding network latency between components and this adds up. Therefore, we took the decision to cut down the number of components in our system. The two changes we made to do this were:
- Packaging the Pricing Service and Pricing Model applications together in one JVM Both applications are written in Java so rather than having two separate lambdas we included the Pricing Model as a packaged dependency within the Pricing Service Lambda
- Bypassing the Opinion API and getting data straight from the DynamoDB via the AWS SDK The API was useful because it included some validation but bypassing it means that our requests stay within AWS’s network rather than us going out to the public internet just to access our database.
Smarter Java packaging
Whilst combining our two jars we took the opportunity to include a couple of other optimisations to our packaging. Firstly, we shrunk our jar size by adding some packaging filters. AWS Lambda requires you to package all of your dependencies within an ‘uber jar’ and we found that with the maven-shade plugin you can add filters to trim this down to just the bits you need. More on this can be found here: Maven Shade Plugin The other optimisation was including the ‘afterburner’ module with Jackson serialization. This speeds up serialising/deserialising between POJOs and JSON when handling requests and can be found here: Afterburner Module
But… what about that network latency? :-O
After our first round of optimisations we were down from 260 to 140ms, not bad eh? At this point, someone suggested something we hadn’t thought to measure yet though - the network latency between AWS and the on-premise datacentre that our service will be accessed from. To test this, we replaced our Pricing Service lambda with a simple ‘hello world’ app that did no calculations, just returned a dummy 3/1 price back to the API. The resulting 95th percentile latency was 124ms. We were over our target without even doing anything!
At this point I went back to the team we were delivering for and discussed our results. This takes me to my first lesson learnt in optimising performance: Make sure your performance targets are realistic. Find out if they are hard limits or soft targets. Knowing this is important because it informs you when it is ok to stop optimising and move on. Do you make major design changes or can you just change your requirements to something more lenient? Also, it’s good to measure the external and internal latency of your system (with and without network latency.) If the internal latency is what’s in your control then that’s what you should be looking at, even if it’s external that your customer cares about.
As it turns out, the sportsbook team that we were delivering for suggested that anything close to 125ms would be fine, and they also suggested changing our tests to keep connections alive between requests as this would cut down on network costs. We made this change and this took us down to 110ms, excellent news!
Uh oh… things aren’t as they seem :-(
Now under our revised target, we were about to wrap up the project when someone noticed something odd. Our DynamoDB table only had opinion for 1 fixture in despite the test saying it had created 100 :scream: Uh oh! It turns out we had a typo in our Node code in the performance test which had slipped through review. This takes me to my second lesson learnt: Test your performance test code as if it were production code!
By only using one fixture in our test, we were regularly hitting the in-memory cache and not performing many model calculations. We fixed the bug and reran the test – we were back up to 260ms from a revised baseline of 320ms :-( Back to the drawing board!